INVESTIGACION Y DESARROLLO DE PROPUESTAS DE MEJORA
Extended Dense Video Captions Using Input Clipping in a Bi-modal Transformer
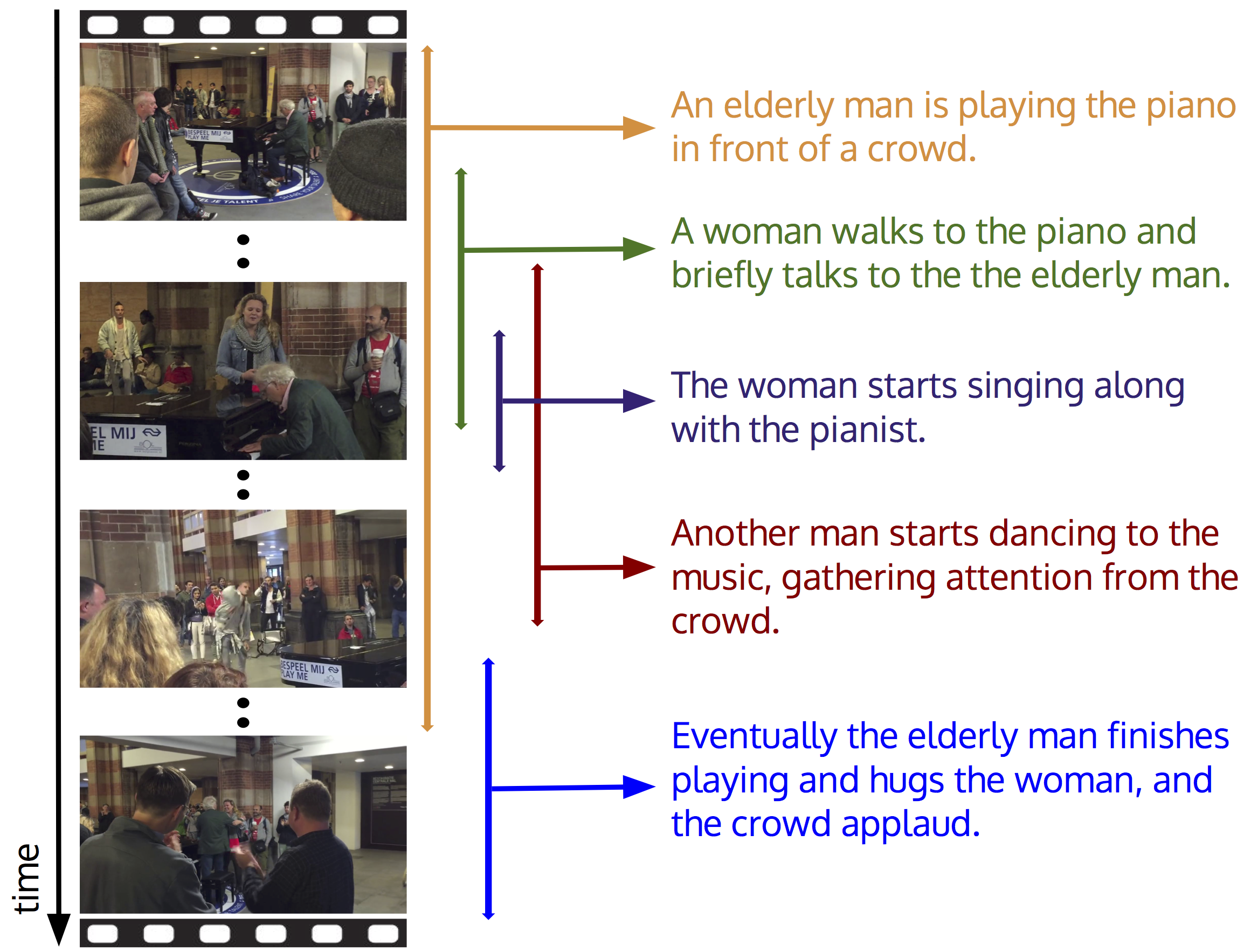
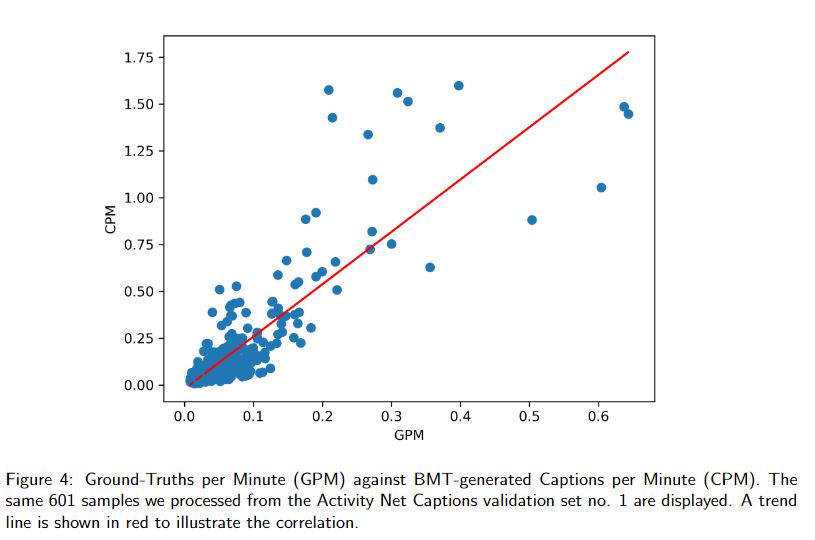
The ability of educators to adapt classroom activities in response to student behavior during class is constrained to human limitations, especially when the student-to-professor ratio is high. \textit{Smart classrooms} use monitoring devices that generate visual and audio data which can be analyzed by deep learning models, surpassing such human limitations. Dense Video Captioning, the task of localizing and describing multiple events in videos, is applicable in this context. One of the state-of-the-art models, the Bi-modal Transformer, can be implemented with input clipping to extend the amount of events it describes. With preliminary results, we achieve an increase of the amount of descriptions generated in each of the samples.

Contacto
Oscar Miranda Escalante A01630791@tec.mx +52 1 33 3465 9159 Leyre Carpinteyro Palos A01610296@tec.mx +52 44 4143 0013